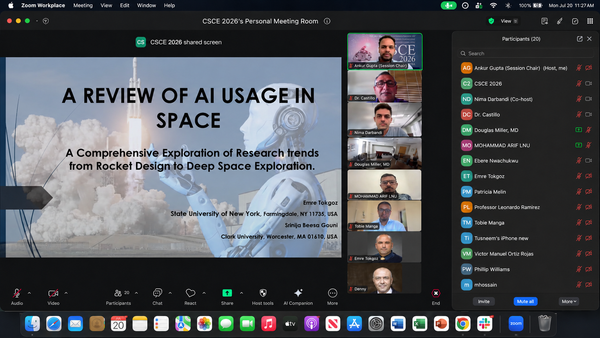
APIs and Services

How software talks to software, from the first request to a payment that never double-charges
Almost nothing you use is a single program. Your banking app is dozens of programs. So is your ride app, your email, the website you bought coffee filters
from last night. They are built out of many small pieces, often run by different teams, that constantly talk to each other. The language they talk in is the API, and the way the pieces are divided up is into services.
This is the most important plumbing in modern software, and it is where a huge share of cross-team problems come from. So we are going to go slow and build it up properly: what an API actually is, what a request and a response are made of, the handful of verbs and status codes you will see for the rest of your life, the three main API styles and when each is used, how systems prove who you are, how they avoid charging your card twice, and how one service tells another that something happened. By the end you will be able to follow almost any API conversation and ask the question that actually matters.
An API is a menu
Start with the simplest possible picture. An API (the letters stand for application programming interface, but ignore the words) is a menu. A restaurant menu tells you what you can order and how to ask for it, and it hides the kitchen completely. You say "number 7, no onions," and a plate comes back. You never see the chef, the fridge, or the recipe.
Software works the same way. When your weather app shows tomorrow's forecast, it sent a request to a weather company's API that said, in effect, "give me the forecast for zip code 94040." A reply came back with the data. Your app never saw their code, their databases, or their servers. It read the menu and placed an order.
This is the whole reason APIs matter. The menu is a promise. As long as the kitchen keeps honoring the menu, it can change everything behind it, rewrite the code, swap the database, move to new servers, and every app that orders from it keeps working. The menu, not the kitchen, is the contract. Hold that thought, because almost every API problem is really a menu that changed while someone was still ordering from the old one.
What is actually in a request and a response

Let us open up a single API call and look at the parts, because once you see them, a lot stops being mysterious. Every call has two halves: the request you send, and the response that comes back.
Say your app wants the recent orders for user number 42. It sends a request with four parts.
First, the method, also called the verb. This is what you want to do. Here it is GET, which means "read something, change nothing."
Second, the path, which is the address of the exact thing you want: /users/42/orders. Read it left to right like folders: the users collection, user 42, that user's orders. Clean APIs read almost like a sentence.
Third, the headers. These are little labels on the envelope that carry information about the request rather than the request itself. The most important one is usually Authorization, which proves who you are (more on that soon). Another common one, Accept, says what format you want the answer in, usually JSON.
Fourth, the body. This is the actual content you are sending, and for a GET it is empty, because you are only reading. When you create something, say placing an order, the body carries the new data.
Then the server answers, and the response has three parts: a status code (a number that says how it went, like 200 for "OK"), its own headers, and a body, which holds the data you asked for, almost always as JSON.
A quick word on JSON, since it is everywhere. JSON is just a simple, readable way to write data as labeled values, like { "id": 1, "total": 19.99 }. People can read it, machines can read it, and that is why nearly every modern API speaks it. When an engineer says "what does the payload look like," they mean "show me the JSON."
That is an entire API call. A request with a verb, an address, some labels, and maybe a body; a response with a status, some labels, and the data. Everything else in this article is detail layered on top of this one skeleton.
The round trip, and why "chatty" is slow

Now watch what happens in time. Your request leaves the phone, travels across the network to the server, the server does some work (maybe it reads a database), and the answer travels all the way back. That whole there-and-back is one round trip, and it is the single most useful idea for understanding why software feels fast or slow.
A round trip is not free. Even on a good connection, the back-and-forth might take 50 to 100 milliseconds, most of it just travel time. One round trip, no problem. But here is the trap: if a screen needs ten separate API calls to load, and it makes them one after another, you have stacked ten round trips, and now the user stares at a spinner for a full second for no good reason.
This is why engineers care so much about being "chatty." A chatty design makes many small calls; a coarse design makes fewer, bigger ones. A common performance fix is simply collapsing ten calls into one, or firing them all at the same time instead of in sequence. So when someone says "the app is slow because it is too chatty," this is exactly what they mean: too many round trips, stacked up. You now have a real lever to ask about.
The five verbs and the numbers that come back

There are only five verbs you need to know, and they map to the four things you can do with any piece of data: create it, read it, update it, delete it (engineers call this CRUD).
GET reads something and changes nothing. This is special: because it changes nothing, you can repeat a GET as many times as you like with no harm. Refresh a page ten times, no damage.
POST creates something new, like placing an order or signing up.
PUT replaces something completely, and PATCH updates just part of it. The difference is small but real: PUT swaps the whole record, PATCH changes one field.
DELETE removes something.
The reason this matters beyond trivia: GET is "safe" and the others are not. POST, PUT, PATCH, and DELETE change data, which means doing them twice can cause real damage (two orders, a double charge). Hold that thought; it comes back when we talk about retries.
Now the answer. Every response carries a status code, a three-digit number, and they come in families you can read at a glance.
The 200s mean success. 200 is "OK," 201 is "Created."
The 300s mean redirection, usually harmless. 304 means "nothing changed, use your cached copy," which is part of how the web stays fast.
The 400s mean you, the caller, made a mistake. 400 is a malformed request. 401 means "I do not know who you are" (you are not logged in). 403 means "I know exactly who you are, and you are not allowed." 404 means "that thing does not exist." 429 means "you are asking too fast, slow down."
The 500s mean the server broke, not you. 500 is a generic crash; 503 means the service is down or overloaded.
Here is the one distinction worth memorizing, because it settles arguments: 4xx is the caller's fault, 5xx is the server's fault. When two teams are pointing fingers over a failing integration, the status code usually tells you whose bug it is. A wall of 401s means the calling team has a credentials problem. A wall of 500s means the serving team's system is falling over. That single number routes the issue to the right owner.
REST, GraphQL, and gRPC: three ways to ask

You will hear three style names constantly. They are just three answers to the question "how should the menu work." Let us use one concrete goal for all three: get a user's name and their last three orders.
REST is the classic style, and most public APIs use it. In REST, everything is a "resource" with an address, and you act on it with the verbs above. It is simple, predictable, and works everywhere. Its weakness shows in our example: to get the name and the orders, you often make two calls (one for the user, one for the orders), and each call hands back a fixed shape, so the user call probably returns the whole user, email, address, settings, avatar, when you only wanted the name. Getting more than you need is called over-fetching; needing another call to get something is under-fetching. With REST you live with both.
There is a sharper version of this called the N+1 problem, worth knowing by name because it quietly kills performance. Imagine you fetch a list of 50 orders, then make one more call per order to get its product details. That is 1 + 50 = 51 calls to draw one screen. Fifty-one round trips. The N+1 problem is the classic cause of a page that mysteriously takes forever, and the fix is to fetch in bulk instead of one at a time.
GraphQL was built to solve exactly this. Instead of fixed menu items, the client writes a precise query describing the exact fields it wants, the name and the last three orders with just their id and total, and gets back exactly that, no more, no less, in a single call. One round trip, no waste. The cost is more complexity on the server and a steeper learning curve, so it shines when you have many different screens all needing different slices of the same data, which is why large apps with hungry mobile and web clients often adopt it.
gRPC is the third style, and it is built for speed between a company's own services, not for the public web. Instead of human-readable JSON, it sends compact binary that is faster to send and to parse, and it is strict about the exact shape of every message. You would not expose gRPC to a web browser, but for two internal services talking millions of times a second, that efficiency is exactly what you want.
The takeaway is not to pick a favorite. It is that the choice is about who is calling and what they need: REST for broad public simplicity, GraphQL for flexible clients that want precise data, gRPC for fast internal service-to-service traffic.
Proving who you are: authentication
So far we have ignored a basic question: how does the server know it should answer you at all, and that you are allowed to see user 42's orders? That is authentication (who you are) and authorization (what you are allowed to do), and there are three mechanisms you will hear about.
The simplest is an API key, a long secret string you send with every request, like a password for your app. Fine for server-to-server use, but if it leaks, anyone can pretend to be you.
OAuth is the one behind every "Sign in with Google" or "let this app access your calendar" screen. The genius of OAuth is that you can grant one app limited access to your data on another service without ever giving it your password. Think of a valet key, the one that starts the car and opens the door but not the trunk or the glovebox. You hand an app a valet key to your calendar: it can read your events and nothing else, and you can revoke it any time. That is why you should care when an app asks for broad permissions; OAuth is supposed to keep the key small.
JWT (people say "jot") is a common format for the token you carry around once you are logged in. The clever part is that it is tamper-evident: it is digitally signed, so the server can instantly tell if anyone changed it, like a wristband at an event that cannot be faked or altered. It lets a server trust you on each request without looking you up in a database every single time.
You do not need to implement any of this. You need to recognize that a wall of 401 errors is an authentication problem (keys or tokens wrong or expired), and that when an app requests broad permissions, that is a real privacy and security decision, not a checkbox.
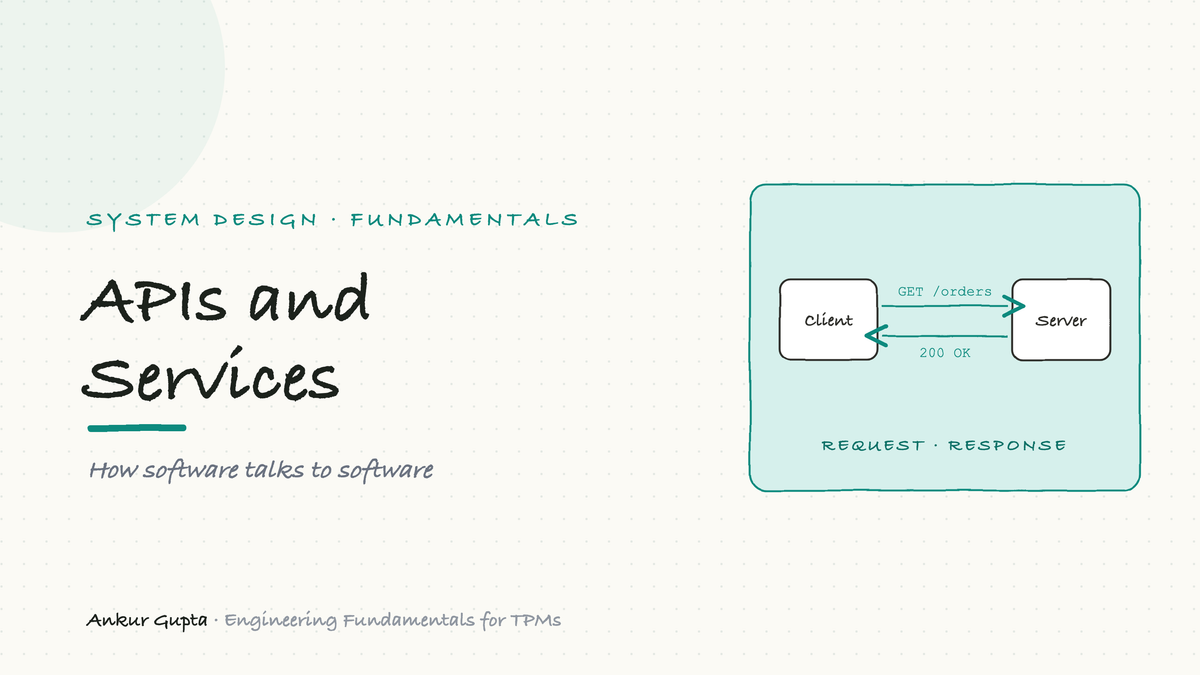
The front desk: an API gateway
Once a system is made of many services, you do not let the outside world talk to each one directly. You put a single guarded front door in front of all of them, called an API gateway, and every outside request goes through it.
The gateway does the jobs that every service would otherwise have to repeat. It handles authentication (checking who you are, once, at the door). It does rate limiting (making sure no one hammers you too fast). It does routing (sending each request to the correct service behind it). And it can do aggregation (calling several services and combining the results into one answer, so the client makes one call instead of five).
The picture to keep is a building with many rooms and one reception desk. Visitors do not wander the halls; they check in at the desk, which verifies them and points them to the right room. It is safer (services are hidden from the internet), simpler (shared chores happen in one place), and easier to change (you can move rooms around behind the desk without anyone outside noticing).
Designing an API that people do not hate
A few design choices separate an API that is a pleasure to build against from one that causes a steady drip of tickets. None of these are technical in a way you cannot follow.
Consistency. The whole API should feel like it was designed by one person. If one part says /users and another says /getCustomerList, every developer has to stop and look things up. Boring consistency is a feature.
Pagination. Never return a million rows. If someone asks for "all orders," you hand back a page at a time, say 50, with a pointer to the next page. Without pagination, one innocent request can try to load everything and knock the system over. When you hear "we need to paginate that endpoint," it means something is returning too much at once.
Rate limiting. An API protects itself by capping how often any one caller can hit it, and answers 429 ("too many requests") when you cross the line. This is the bouncer at the door. It stops both abuse and the far more common problem: a buggy client stuck in a loop, calling a million times by accident. Rate limits are why a runaway script gets throttled instead of taking everyone down.
Versioning. This is the big one. Remember that the menu is a contract. The moment you change it in a way that breaks existing callers, removing a field, renaming something, requiring a new parameter, you have made a breaking change, and everyone still using the old menu breaks. The disciplined fix is versioning: you publish a v2 while keeping v1 running, and give people time to move. Adding a new optional field is safe (non-breaking). Removing or renaming is not. When an engineer says "this is a breaking API change," your antenna should go straight up, because that is a cross-team coordination project with a migration and a deadline, not a quiet code tweak.
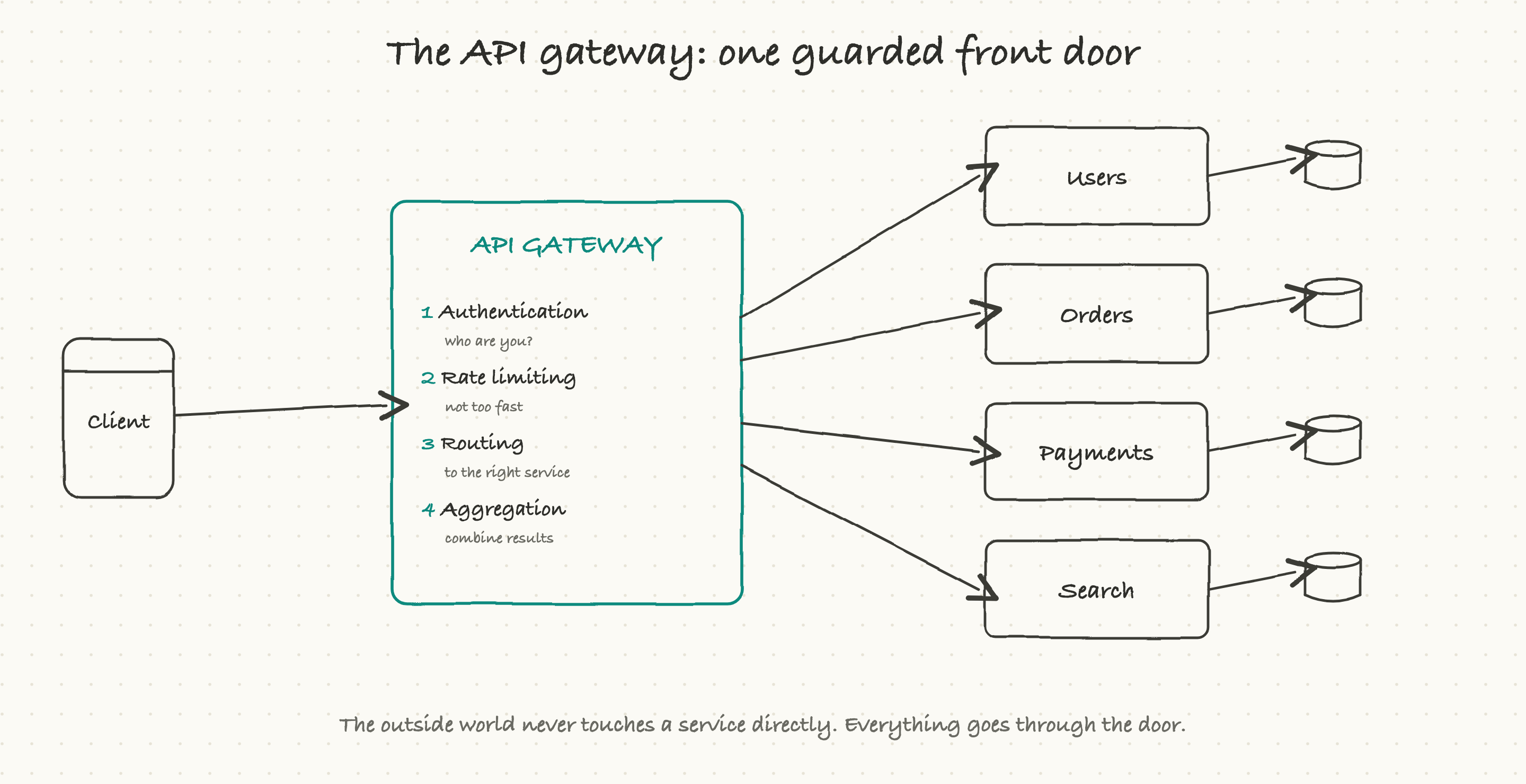
Why a retry does not charge you twice: idempotency
Here is a problem that sounds small and is actually one of the most important ideas in all of API design. Networks are unreliable. You send a request to charge a card $20, and then the connection drops before the reply comes back. Now the app is in an awful spot: did the charge go through or not? It genuinely cannot tell. If it assumes failure and retries, it might charge you twice. If it assumes success and the charge never happened, someone got something for free.
The fix is a property called idempotency, a long word for a simple promise: doing the same thing twice has the same effect as doing it once. A GET is naturally idempotent (reading twice changes nothing). The trick is making a charge idempotent too.
The way it works: the app attaches a unique key to the action, say key=abc123, and sends it with both the first attempt and any retry. The server remembers keys it has already processed. When the retry arrives with abc123, the server thinks "I have already done abc123," and instead of charging again, it just returns the same result as the first time. One key, one charge, no matter how many times the request is sent.
This is exactly how serious payment systems stay safe, and it is one of the best things to ask about whenever money or anything irreversible is involved. "Is this operation idempotent? What is the idempotency key?" is a question that has saved many launches from a very bad day.
Telling another system that something happened: polling vs webhooks

The last piece. Often one system needs to know when something finishes in another: a payment clears, a video finishes processing, an order ships. There are two ways to find out, and the difference is real money and load.
The first way is polling: the client keeps asking, "is it ready yet? is it ready yet?" over and over until the answer is finally yes. It is simple, but wasteful: almost every one of those calls is answered "no," so you are burning requests and time, and you still find out a little late (whenever your next check happens to land).
The second way is a webhook: instead of asking repeatedly, the client registers once, saying "here is my address, call me when it is done." Then it waits and does nothing, and the moment the work finishes, the other system makes one call back to deliver the news. One message, no waste, and you find out the instant it happens. Polling is calling the bakery every five minutes to ask if your cake is ready; a webhook is leaving your number so they call you when it is.
Webhooks are more efficient and more timely, which is why they power most integrations between systems (payment confirmations, shipping updates, chat notifications). The tradeoff is that they are a little harder to build: the receiver has to be reachable, has to handle the same notification possibly arriving twice (idempotency again), and usually verifies that the call really came from who it claims. But when you hear "we will get a webhook when the payment settles," you now know exactly what that means and why it beats checking on a timer.
What actually goes wrong
Put it together, and you can predict most API incidents before they happen:
The breaking change. Someone ships a "small" change to a widely used API, and three teams downstream break at once because the menu changed underneath them. This is the most common cross-team fire, and it is entirely preventable with versioning and communication.
The N+1 explosion. A screen quietly makes one call per item and grinds to a halt under real data. Looks like a mystery slowdown; is really too many round trips.
The retry storm. Something gets slow, every client retries at once, the retries pile onto the already-struggling service, and it collapses harder. Without idempotency and sensible retry limits, the cure becomes the disease.
The leaked key. An API key ends up in public code, and suddenly someone is using your account. This is why keys are rotated and scoped.
Why a TPM should care, and what to ask
APIs are the literal contracts between teams, so they are where cross-team work succeeds or fails. You do not need to design them. You need to hear the risk in the room and ask a few sharp questions at the right moment:
Is this a breaking API change? If yes, who depends on the old version, and what is the migration plan and deadline?
For anything involving money or irreversible actions: is it idempotent, and what is the key?
For a slow screen: how many API calls does it make, and are we stacking round trips or hitting an N+1?
For a new integration: are we polling or using a webhook, and have we set sensible rate limits?
For permissions: what scope is this token actually granting, and can we make it smaller?
Ask those, and you will be the person in the room who sees the cross-team landmine three weeks before it goes off. Which is the entire job.