Leading 200 Teams Without Managing a Single One


Centralize the information, decentralize the work
When I joined the a major tech company in 2022, reliability worked the way it does at a lot of places that copied the early Google model: a large site reliability engineering organization, with SREs embedded across every product. The split was simple on paper. Product teams built the software; SREs kept it running, on-call, incidents, scaling, the operational load.
That model has two problems. It does not scale, and it separates the people who build a system from the people who keep it alive. Scalability and operability should be built into a product from day one, by the people building it. When they are bolted on afterward by a separate team, you get products that were never designed to be operated, and someone else inherits the pain.
So the goal was to flip it. Product teams would own the reliability of their own products, and the reliability organization would stop being a support arm and become a platform arm that builds the tools to make reliability easier for everyone. That is not a tweak. It is a company-wide culture change. You are not changing fifty or sixty reliability teams; you are changing every engineer on every product team, because now they all have to operate what they build. That is two or three hundred teams.
I was hired as the TPM to make it happen, and I want to be honest about what I walked into.
The three problems nobody had solved
Nobody could tell you what "done" looked like. Only a few people at the center understood the end state. The biggest problem in the program was not how. It was what.
There was no way to see progress. Updates were manual and verbal. A director would ping teams every week, "what's your update," and someone would say "we're making progress," and that was it. Nothing was tied to anything, no way to know if we had moved week over week.
Leadership was nervous. Dissolving a whole category of teams scares people about their jobs, so the instinct was to keep it vague and slow: "this is a five or ten year thing." I do not work like that. If something is worth doing, you find the opening and you go.
The principle I build every program around
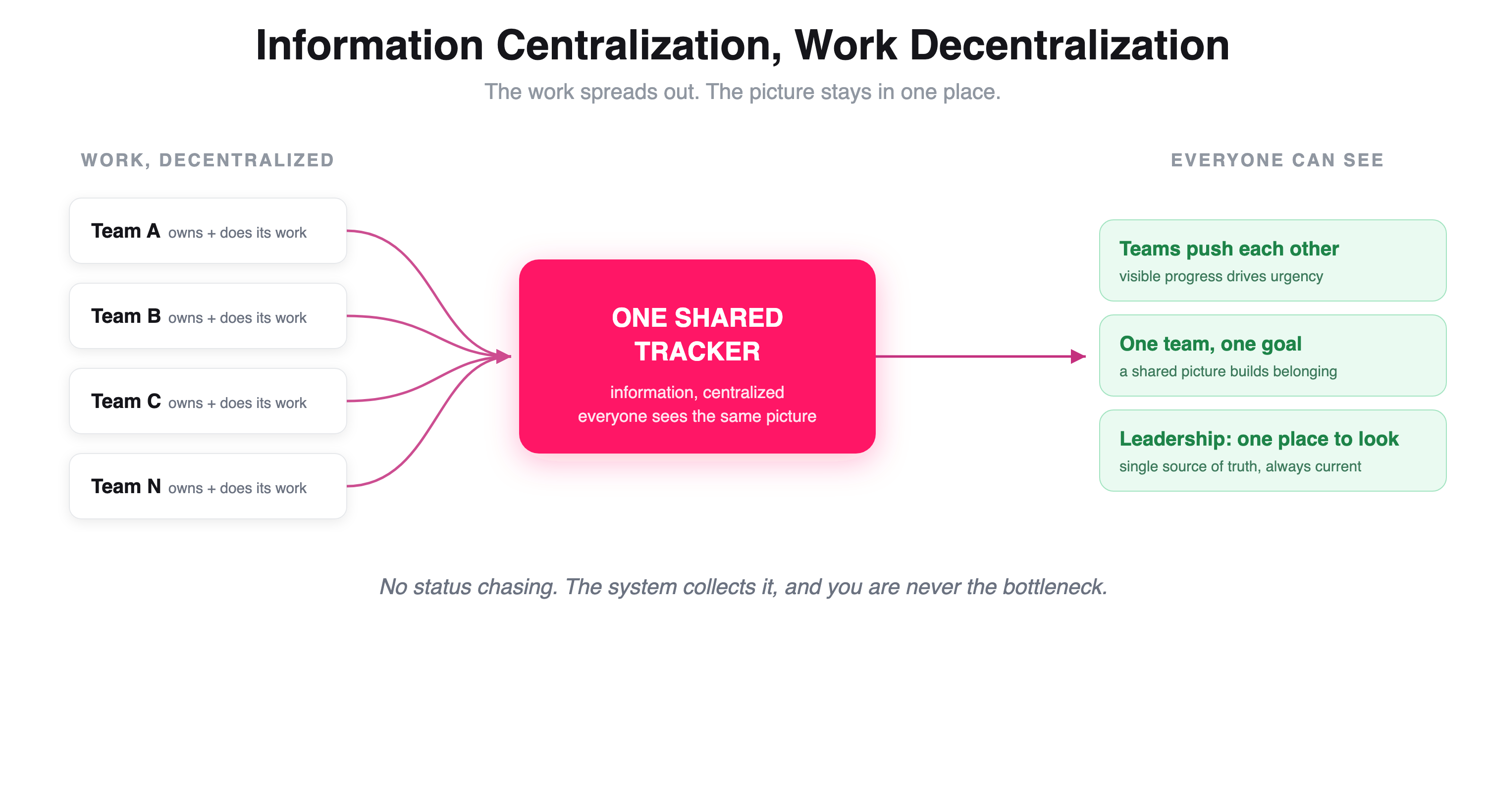
Before I tell you what I built, I have to tell you the principle behind it, because it is the same one I bring to every program I run. I call it information centralization, work decentralization. I have not heard anyone else put it quite this way, but I believe in it completely, and it is the thing that lets me lead two hundred teams without becoming the bottleneck.
The two halves do opposite jobs on purpose.
Decentralize the work. The actual work should be broken down and handed to the right person, the one who will do it. You do not centralize work; that just makes you the bottleneck. You find the right owner for each piece, and you assign it.
Centralize the information. Everything about that work, what is being done, by whom, and where it stands, lives in one place that everyone can see. Not just me. This is the part people get wrong. A status system is not for the TPM; it is for the whole team. Everyone should be able to see what is happening on the ground at any time, and everyone should have a dead-simple way to update where they are.
And I mean dead simple. The tools we use in program management should never be a barrier to giving an update. Ideally, nobody should have to give one at all; the system should collect the status on its own. When a human does have to update, it should be the bare minimum, a small formality for leadership, nothing more. Teams should spend 99.99% of their time on the work and almost none of it reporting on the work. The day status reporting becomes a second job, you have already lost.
What I built
With that principle in hand, the fix almost designs itself. I built one centralized tracker. Nothing fancy, a single, very deliberately designed sheet, and I built it so the information lived in one place while the work stayed spread across the teams who owned it.
Here is the mechanic. We had four or five orgs, each under a director. For each org, every reliability team listed the activities they actually do today, all the operational work they own. For each activity, we named the role and the product team that would take it over. The reliability team trains that product team, and the moment the product team can do it themselves, the activity is marked done.
That one design choice changed what we were measuring. If a team had fifty activities to hand off, those fifty became the metric. I stopped asking "what did you do this week" and getting a story, and started asking "how many of your fifty are transitioned," where there is nowhere to hide. New activities joined the list; finished ones turned green; and the day a reliability team marked a product team at one hundred percent, I went to that product team and said: your support is gone, your own reliability team just told me you do not need them anymore.
Notice what that did. It took me and the central committee completely out of the business of chasing status. I did not gather updates. The system did. That is the two halves working together, the work sat with the teams, the picture sat in one place, and I was free to actually lead instead of chase.
Why centralizing the information is the real unlock
The tracker did far more than save me time. Once everyone could see everyone, three things happened that I did not have to engineer.
Teams started pushing each other. When a team could see that one org was at fifty percent while they were still at ten, it lit a fire. Nobody wants to be visibly behind. That comparison drove more urgency than any nudge from me ever could. It also let teams learn from each other, look at how the team ahead of them did it, and borrow the approach instead of inventing their own from scratch.
People felt like one team. This one surprised me. When the information lives in one shared place, everyone feels like part of a single effort moving toward the same goal. When it is scattered across a dozen docs and threads, people still do the work, but they feel alone in it. Centralizing the information created a sense of belonging that a disparate setup never does.
Leadership always had one place to look. Directors and VPs stopped asking me for status, because they could open the tracker and see exactly which org was moving and which was stuck. One source of truth, always current, always available. That is worth more than any deck I could ever build.
The fundamentals still have to be in place
The framework is the engine, but an engine still needs a chassis. None of this works if the basic TPM fundamentals are missing. Here are the ones that mattered most on this program.
Make the goal undeniable. Remember, the biggest problem here was not how, it was what. So before anything else, I nailed down a single, shared definition of done that an executive and an engineer could both read and agree on: every product team operates its own services, and the reliability org becomes a platform org. When people stop arguing about what we are doing, they can finally start doing it.
Get air cover, and spend it sparingly. A culture change that threatens people's jobs cannot survive on a TPM's energy alone. I made sure I had a senior sponsor who would say "this matters, and it is happening this year" in the rooms I was not in. But I treated that air cover like a fire alarm. Pull it too often and it stops meaning anything. The threat of escalation, held in reserve, did more than the act of escalation ever did.
Run the cadence on the metric, not the narrative. Once the tracker turned the work into numbers, the reviews changed. Instead of a room full of verbal updates, we reviewed movement: who advanced, who stalled, and what was blocking the ones who stalled. A short, regular rhythm tied to a real metric is what keeps a multi-year program honest week over week.
Make the decisions explicit. At this scale you constantly hit priority conflicts, a team that genuinely cannot take on the transition this quarter because of a launch. The job is not to win that fight personally. It is to surface the decision to the people who own priorities, with the data laid out plainly, and let them make the call. You are escalating a decision, not a person.
Manage the dependencies as real work. Some teams could not transition until a platform capability existed, a piece of tooling, a runbook, a safeguard. I tracked those dependencies as first-class items, because a transition gated on something that does not exist yet is not a transition. It is a wish.
You cannot scale if you are the bottleneck
Get those fundamentals right and you have a program. But fundamentals alone do not scale to two hundred teams if every thread still runs through you. The only way I know to lead at that scale is to build a hands-free framework early: centralize the information so everyone can see, decentralize the work so the right people own it, and make the whole thing run without you standing in the middle of it.
Do that, and leading two hundred teams stops feeling like heroics and starts feeling almost automatic. You will never have authority over two or three hundred teams, and you do not need it. You need to build the system that points them all at the same goal and lets them watch themselves get there. Authority could have pushed sixty teams for a quarter. The framework moved the whole company, and it kept moving without me.
How to cite this:
Gupta, A. (2022). Leading 200 Teams Without Managing a Single One. Ankur Gupta. https://ankurgupta.me/leading-200-teams-without-managing-a-single-one-2/
This work is licensed under CC BY 4.0 — you're welcome to share and adapt it, with credit to Ankur Gupta and a link back to this original post.