Managing Dependencies Across Teams


Make every dependency explicit, tracked, and owned
Unmanaged dependencies are the number-one cause of preventable program slips. Not technical complexity, not headcount, not changing requirements. Dependencies. And here is the frustrating part: they are also the most predictable risk in any large program. A dependency that slips rarely surprises anyone who was actually watching it. Which means failing to manage them is not bad luck. It is a choice.
After running programs with hundreds of cross-team dependencies, I stopped treating this as a coordination chore and started treating it as the core of the job. My rule is simple: I make every dependency explicit, tracked, and owned. That is the whole game, because almost every dependency disaster I have seen is a failure of one of those three.
Dependencies go wrong in exactly three ways.
The three ways dependencies kill programs
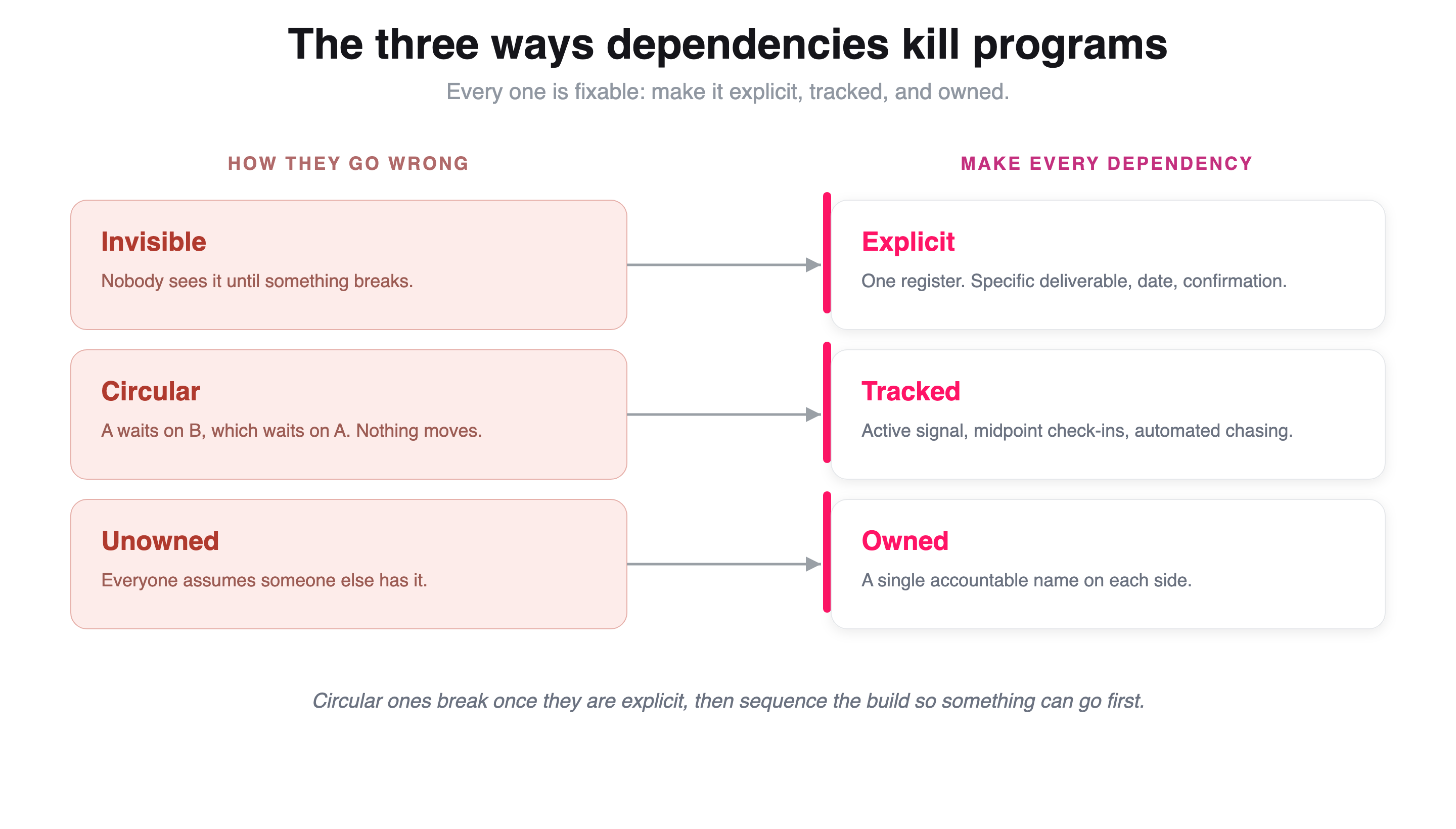
They are invisible. Two teams depend on each other and neither one knows it until something breaks. This is the most common and the most dangerous, because you cannot manage a dependency you cannot see. I have watched two teams ship into the same release both assuming the other owned a shared piece of config. Nobody owned it. It surfaced in production. I have seen an engineer agree in a chat thread to build a small integration for another team, never write it down anywhere, and the dependent team find out three weeks before launch that the thing they were counting on does not exist. The work was real. The dependency was invisible.
They are circular. Team A is waiting on Team B, which is waiting on Team A. Everyone is blocked, everyone is technically busy on their own piece, and the whole thing sits still. On a large data-center build I led, bringing more than two hundred services up in a new region, the control-plane services were knotted with circular dependencies: A could not start until B was up, B needed C, and C was waiting on A. Nothing could go first. If you do not find those loops early, they detonate at the worst possible moment, the day you are trying to actually turn the region on.
They are unowned. Everyone assumes someone else is handling it. The dependency is known, it might even be written down, but there is no single name attached on either side, so it drifts. "Platform will do the backfill." Platform thought the product team owned it. A month goes by and nobody has touched it, because "the team" is not a person, and only people do work.
Make a dependency explicit, tracked, and owned, and you close all three holes. Here is what that looks like in practice.
Make it explicit
The first move on any program is to drag every dependency into the open. I keep a single dependency register, a living list every lead can see and that we walk in every program sync. Each row names the providing team, a single contact, a specific deliverable, a date, a status, and the date of the last update.
That register only works if the deliverable is specific. "An API by May" is not a dependency, it is a wish. "A REST endpoint with auth, documented, deployed to staging, load-tested to a thousand requests a second, by May 20" is a dependency. When I set one up, I have a real conversation with the providing lead, agree on that exact definition and date, write it down, and send it back with "please confirm this matches your understanding." A dependency that is not written down and confirmed is not explicit. It is a hope two people happen to share.
And for the invisible ones, I do not just wait for teams to declare dependencies, I go hunting. In every weekly review I ask the one question that surfaces more hidden dependencies than anything else: "Did any new dependency form this week that is not on the register yet?" That is where the chat-thread integrations and the quiet handshakes come out of the dark.
Track it, and automate the tracking
Most dependency failures are not failures of effort. They are failures of signal. Team A waits passively, assumes Team B is fine, and finds out at week minus one that B deprioritized the work three weeks ago. The fix is to track actively. The best health indicator I know is the "last update" date: a dependency I have not heard about in three weeks is not on track, it is unmonitored. That is the signal to pick up the phone, not send another email. And I always set a check-in at the midpoint, not the deadline, because a team with bad news at the midpoint can usually still recover, and a team with bad news a week out usually cannot.
But here is the thing nobody tells you: at real scale, manual tracking collapses. On my largest programs the leads and I were drowning, hundreds of tickets across many orgs, endless follow-ups, status gathered by hand. We were burning five to ten hours a week just chasing, and dependencies were still slipping through the cracks. So I did what I always end up doing. I stopped chasing and built the system to chase for me.
I designed and built an automated dependency-tracking platform from scratch. It created dependency tickets in bulk across orgs, sent reminders on a configurable cadence over chat and email, filed escalation tickets at the org level when something went red, and rolled everything into one dashboard that showed dependency health in real time. Teams updated their own status in place, so nobody had to be chased for it. We ran it across the two-hundred-team region build and a hardware-forecasting program spanning a couple dozen teams, and together it tracked hundreds of dependency tickets. It gave back those five to ten hours a week, and far more importantly, it turned dependency health into something everyone could see at a glance, so we could step in before a blocker became a crisis. Same principle I bring to every program: centralize the information, and let the system do the chasing.
For circular dependencies, "explicit and tracked" is exactly what lets you break them. Once you can see the whole graph, the loop becomes obvious, and then you have options: sequence the build into tiers so something can go first, or break the cycle with a temporary stub that lets one side stand up before the other. On that region build, we cleared the large majority of the circular and critical dependencies by laying out a strict, tiered build order. You cannot untangle a knot you cannot see. Visibility is what makes the fix possible.
Give it an owner, and negotiate honestly
The cure for unowned dependencies is a name. Every dependency gets a single owner on each side, the person actually accountable, not "the team." If I cannot tell you who owns a dependency, it is unowned, no matter how nicely it is documented.
And owners have to be honest with each other, because sometimes the dependency you need is bigger than the other team can give. On one hardware-forecasting cycle, a data-infrastructure org needed two sizable capabilities from the platform team: automated hardware conversion for one class of forecast, and automatic identification of downstream systems so nothing got missed. Both were real, both were big, roughly a quarter of work each, and neither was on the platform team's plan. I could have escalated and tried to force it. Instead I sat down with both sides, understood what each actually needed, and found the middle: we de-scoped to the few most critical pieces and made some deliberate design tradeoffs, while keeping forecast accuracy intact. That saved the data-infrastructure teams from going back to doing those conversions and chasing down every downstream system by hand, and it did not blow up the platform team's quarter. A dependency you negotiate down to its critical core ships. A dependency you demand in full often does not.
The discipline, not the luck
Programs that hit their dates reliably are not lucky. They are disciplined about dependencies. Almost every preventable slip I have seen traces back to a dependency that was invisible, circular, or unowned, and every one of those is fixable long before it becomes a crisis. Make every dependency explicit so you can see it, track it so you get the signal early, and give it an owner so someone actually moves it. Do that, and dependencies stop being the thing that sinks your program and become just another part of it you quietly keep under control.
How to cite this:
Gupta, A. (2022). Managing Dependencies Across Teams. Ankur Gupta. https://ankurgupta.me/managing-dependencies-across-teams/
This work is licensed under CC BY 4.0 — you're welcome to share and adapt it, with credit to Ankur Gupta and a link back to this original post.